

Browser storage mechanisms are useful for a variety of reasons:
- logging a user out after a certain time has passed until the last login (then you can keep the last login timestamp)
- keeping the preferences of the user (user-specific settings, such as the light mode or dark mode)
- keeping some additional information about the user that you use inside your app (like name or username)
- caching your static application resources (like HTML, CSS, JS, and images)
Either way, keeping that information on the client-side saves you from an additional and unnecessary server call, and helps you provide offline support. But, there is a limit to the amount of data you can store on the client side. The exact amount can change according to the browser and user settings. There are multiple ways of caching data in the browser, so you got to choose the one that fits your needs, and this article is going to be about that.
What is in this article?
☀ Before we start
Where are they hiding in the browser?
-
Open the Chrome Console (
Command + Option + Jin Mac andControl + Shift + Jin Windows). -
From the tabs above, choose Application, and you can see all of them under the Storage section (Local Storage, Session Storage, IndexedDB, Web SQL, and Cookies).
As you may have noticed how easy it is for you to see the data that’s kept here, it is also easy for the user to delete or modify this data. So when you’re writing your application, keep that in mind, and try not to rely on these guys so much.
To check how much of the storage your application is using, open the Chrome console, and under the Application tab, choose Storage. From here, you can also create custom storage data to simulate how your application will act under harsh conditions like low disk space. To check how much space is available, you can use StorageManager API but be aware that it is not supported by every browser. The estimate method returns a promise that has quota and usage properties (but beware, they are not precise):
navigator.storage
.estimate()
.then((estimate) => {
console.log(
`You have used approximately ${(
(estimate.usage / estimate.quota) *
100
).toFixed(2)}% of your available storage.`
);
console.log(
`You have up to ${estimate.quota - estimate.usage} remaining bytes.`
);
})
.catch((err) => console.log(err));Tiny but important note: The browser storage mechanisms may act differently in different browsers due to the implementation differences, so take it with a grain of salt and check out other resources if you’re looking for a browser-specific property.
Also, Web SQL support has been removed from many browsers, and it is recommended to migrate the existing usage to IndexedDB.
What are Web Workers and Service Workers?
The script file that you link to the HTML file using the <script> tag runs in the browser’s main thread. If the main thread (the UI thread) has too many synchronous calls, it may slow down the application and create a bad user experience. This is where the workers come in handy.
A worker is a script that runs on the background on a separate thread. Web workers are the most commonly used workers, and they don’t have a dedicated job description. They are mostly used to relieve the main thread by taking on the heavy processing or the calculations that are going to take time. The worker script will be separate from the main script and as it has no access to DOM, the data that needs to be processed has to be sent from the main script with the built-in postMessage method. For a basic live web worker example, check out this GitHub repo.
Service workers are specific types of workers that act as a proxy between the browser, the network, and the cache. They can intercept every network request made from the main script. This allows the service worker to respond to a network request by returning a response from the cache instead of the server, therefore making it possible to run the application offline. For a basic live service worker example, check out this GitHub repo.
1. localStorage and sessionStorage (Web Storage)
Browsers that support localStorage and sessionStorage keep localStorage and sessionStorage objects that allow you to save key/value pairs.
The APIs of localStorage and sessionStorage are almost identical. Their main difference is persistence: sessionStorage is very temporary and cleared after a browser session ends (when the tab or the window is closed). Interestingly, data stored in sessionStorage survives page reloads. Data that is stored in localStorage persists until it is intentionally and explicitly deleted.
The Web Storage API is pretty simple and consists of 4 methods (setItem(), getItem(), removeItem(), and clear()) and a length property:
// For sessionStorage, replace localStorage with sessionStorage in the code below
console.log(typeof window.localStorage); // Prints: Object
// Let's cache some data in our localStorage
localStorage.setItem("colorMode", "dark");
localStorage.setItem("username", "cakebatterandsprinkles");
localStorage.setItem("favColor", "green");
console.log(localStorage.length); // Prints: 3
// retrieving data
console.log(localStorage.getItem("colorMode")); // Prints: dark
// removing data
localStorage.removeItem("colorMode");
console.log(localStorage.length); // Prints: 2
console.log(localStorage.getItem("colorMode")); // Prints: null
// clearing local storage
localStorage.clear();
console.log(localStorage.length); // Prints: 0-
Both localStorage and sessionStorage are great for caching non-sensitive application data.
-
Both of them are synchronous in nature and will block the main UI thread. This is why they should be used with caution.
-
Maximum storage limit is around 5MB. (Both provide bigger storage when compared to cookies, which is 4KB of storage space.)
-
They both only accept strings. (But you can work around this by JSON.stringify and JSON.parse as shown here.)
-
They cannot be accessed by web workers and service workers.
-
Stored data is only available on the same origin for both of them. (They use the same-origin policy. For more explanation check out the last subtitle in this article.)
-
localStorage data can be accessed from different tabs if the domain and subdomain are the same, while sessionStorage data cannot be accessed, even if it’s the exact same page.
2. HTTP Cookies
HTTP Cookies are mostly used for authentication and user data persistence. You create a token that is unique for the user and the session and add it to every HTTP request made from the client. One of the reasons to use cookies is to keep track of what the user is doing on the website - such as adding items to your cart in an e-commerce site, or the login information.
Cookies are attached to every HTTP request, so you should be cautious about what you put inside. Storing too much data will make your HTTP requests chonkier, making the application slower than it’s supposed to be.
-
Maximum storage limit is around 4KB, and can only contain strings.
-
They work synchronously.
-
They are not accessible from the web workers but accessible from the global
windowobject.
Providing that a website uses HTTP cookies, the first cookie is created by the server that is being used. The server is also responsible for setting the HTTP header named Set-Cookie to the token that is uniquely created for that session and that user, which consists of a key-value pair. HTTP headers let the client and the server share additional information about the HTTP request that is being made.
// The header has to have the id in some form because you need to uniquely identify the user.
// By default, cookies expire after a session ends, or when the user closes the browser. To persist a cookie and extend its existence, we can use `Expires` attribute that sets an expiration date and prevents the session fixation attacks, or the `Max-Age` attribute. If both of them exist, the `Max-age` attribute has precedence over `Expires` attribute.
// A cookie with a `Secure` attribute is only sent to the server if the request is made by an HTTPS server. This helps to prevent man-in-the-middle (MitM) attacks.
// `HttpOnly` attribute helps to prevent the XSS attacks. Cookies that have the `HttpOnly` attribute cannot be accessed by client-side JavaScript code.
Set-Cookie: id=a96dw8; Expires=Thu, 31 Oct 2021 07:28:00 GMT; Secure; HttpOnly
// You can access the cookies that don't have the HttpOnly flag with client-side JavaScript, using `document.cookies`.
// You can also set new cookies by using `document.cookies` but bear in mind that they will also be missing the HttpOnly flag, so they will not be secure. So do not store sensitive information this way.
document.cookies // will return the existing cookies as a concatenated string.
document.cookies = "dark_mode=true" // Adds another key value pair to your cookie, which is dark_mode=true.Cookies can also be modified by the user or intercepted in transit. For security purposes, the data should always be encrypted, so in any interception attempt, the user’s credentials stay safe. Also, you should never store sensitive information such as passwords in them. There are several points where the communication can be compromised:
- Cross-site scripting (XSS): If a web application is not using enough validation and encryption, an attacker can inject another client-side code to the application, that gives a malicious user access to sensitive information, and the ability to impersonate another user.
- Cross-site request forgery (CSRF): This is an attack pattern that abuses the logged-in user, steal their session, and trick them to execute malicious code which they don’t know anything about. In such a scenario, your user is tricked into a fake site that runs a script or makes requests to your server. People should only be able to use your session if they are working with your views, so that session should not be available on any other page.
- Man-in-the-middle (MitM): A third party impersonates a server and intercepts the communication between a web server and a client, capturing sensitive data such as login credentials or credit card information. It can also possibly alter data while doing so.
- Session Fixation: A third party steals a user’s session identifier (like a cookie) and impersonates the user.
Very simply put, this is how the client authenticates and talks to a server:
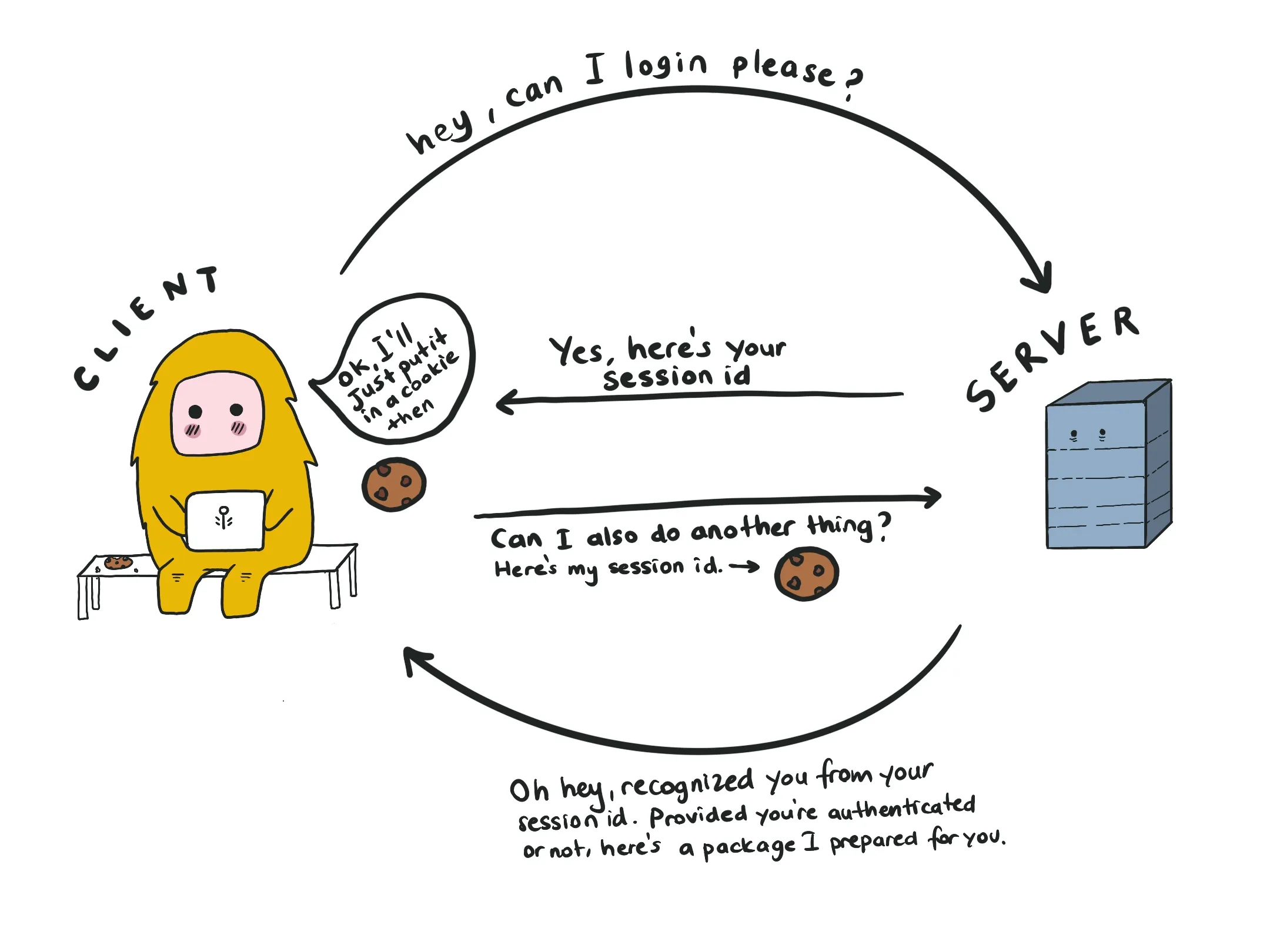
To see if you have any cookies set on your browser, you can visit the Application > Storage > Cookies on your Chrome console. If you want to know more about setting cookies, this article is a good start.
3. The Cache API and IndexedDB API
- The Cache API and IndexedDB API are widely supported in modern browsers.
- Both of them work asynchronously, meaning they will not block the main UI thread.
- They can be accessed from the global
windowobject, web workers, and service workers. - Different browsers have different amounts of quotas. For example, Firefox allows an origin to store up to 2GB, Safari up to 1GB. The quota in Chromium-based browsers depends on the total disk space of the computer that’s being used (around 60% of the total disk space). If you exceed the available quota, both APIs throw you a QuotaExceededError.
IndexedDB API:
- Useful for storing large amounts of structured data on the client side. Keeps the data as key-value pairs.
- You can (and probably should) use an abstraction library (like Dexie.js) to help you use IndexedDB, as it is a low-level API and if used wrong, might break the applications. Check out the other IndexedDB open source projects from here.
Cache API:
- Stores pairs of HTTP request and response objects.
- Useful in Progressive Web Apps. (You can store files that are necessary to make a PWA work, like manifest.json)
For more detailed information, visit here and here.
☀ Same Origin Policy
Same-origin policy is a security mechanism that restricts how one document or script can interact with a document or script from another origin. It defines same-origin as two files using the same protocol, host, and port. If one of them is different, the source is from a different origin, which makes the communication cross-origin.
Let’s give an example. Our fake origin host is: https://smart.monke.com/index.html
`http://smart.monke.com/user/dashboard.html` || Same-Origin, only the path is different
`http://smart.monke.com/index.html` || Cross-Origin, Different Protocol
`https://cute.monke.com/index.html` || Cross-Origin, Different Host
`https://smart.monke.com:81/about.html` || Cross-Origin, Different PortFor security purposes, the API’s that help us make HTTP requests from a server (like XMLHttpRequest and the Fetch API) follow the same-origin policy, so unless a specific Access-Control-Allow-Origin HTTP header is set, they cannot share information with a website of a different origin. This header is returned by the server and it indicates who can use its resources. It can be set to *, which allows any origin to access it (which is less secure), or a specific domain, which allows only that specified domain to access the resource. If you support authentication via cookies, for the server to allow the cross-origin request, it has to set another header named Access-Control-Allow-Credentials. You also have to include the credentials flag to the request in the frontend of the application, or the Fetch API ignores the cookie.
Any cross-origin request that is made from a front end falls into the browser’s hands. The browser sends something called a preflight request to the server, which has no request body, but only headers. This request is only made to confirm that the server will allow such a request from that domain. If the required Access-Control-Allow-Origin is not set, the request fails, and the browser sends back a CORS error. If the header is set and that domain is allowed to make a request, the browser sends the original request and delivers back the response.
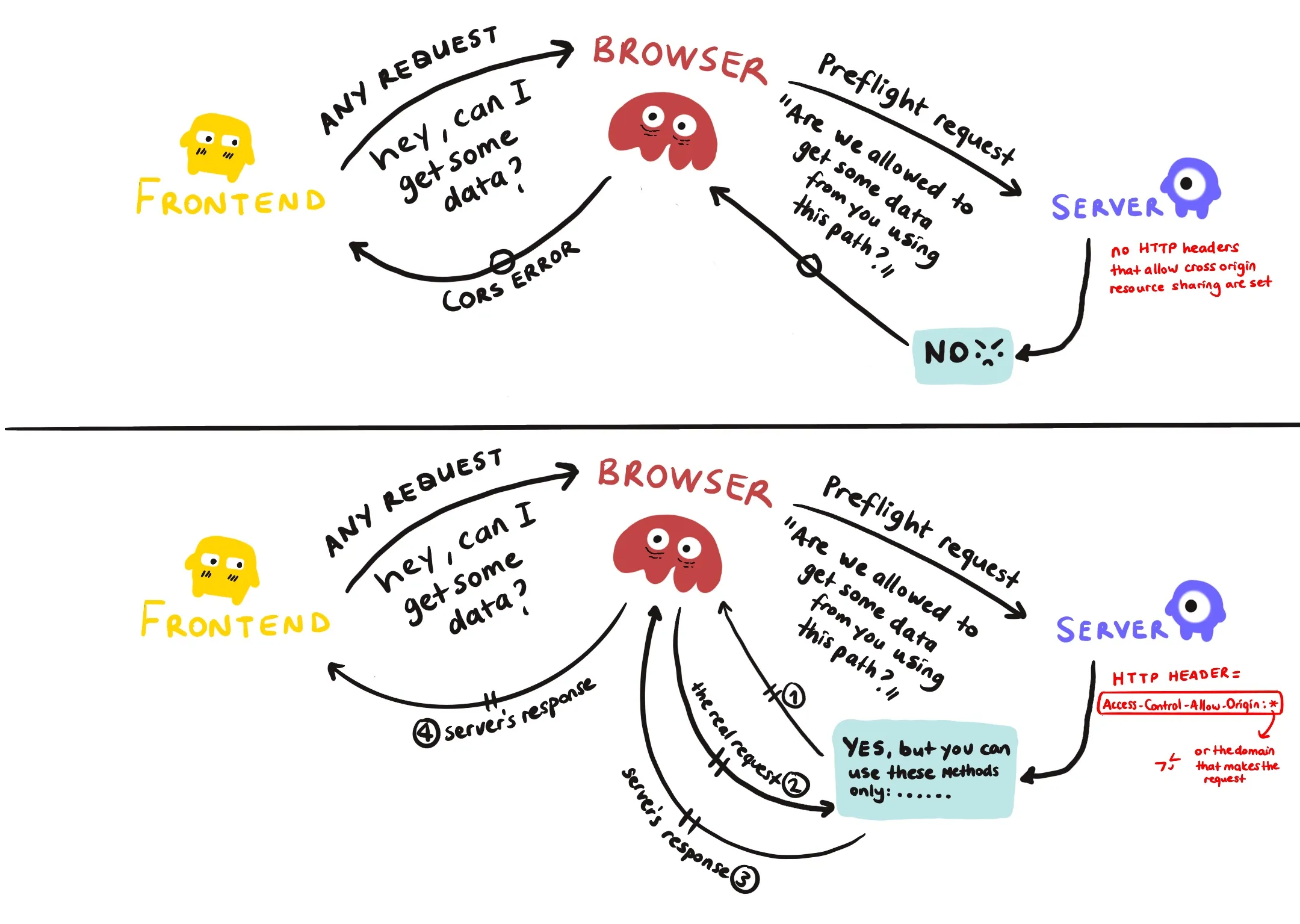
This is not required for the requests made from the backend of the applications. CORS is strictly for the front end of the applications and is applied by browsers to protect the users from cross-site scripting (XSS) attacks. It is quite a controversial subject (as some say CORS doesn’t exist to prevent XSS attacks), but check out this example that explains how CORS helps to prevent XSS attacks quite nicely.
If you want more details on the subject, I recommend this detailed article in MDN Web Docs.
Resources
- Client-side storage, Service workers, Web workers, Cross-Origin Resource Sharing (CORS) by MDN Web Docs
- Storage for the web, The Cache API: A quick guide by Pete LePage
- Best Practices for Using IndexedDB by Philip Walton
- Web workers vs Service workers vs Worklets by Ire Aderinokun
- A practical, Complete Tutorial on HTTP cookies by Valentino Gagliardi
- How does CORS prevent XSS? by StackExchange
- Storage for the web. IndexedDB, Cache API by Alex
